
基本信息
原文标题:F2A: An Innovative Approach for Prompt Injection by Utilizing Feign Security Detection Agents
原文作者:Yupeng Ren
作者单位:Institute of Information Engineering, Chinese Academy of Sciences, Beijing, China
关键词:提示注入攻击、安全检测、伪造安全结果、LLM漏洞、F2A攻击
原文链接:https://arxiv.org/pdf/2410.08776
开源代码:暂无
论文要点
论文简介:这篇论文研究了大语言模型(LLMs)在内容安全检测领域的广泛应用,尤其是其与安全检测代理结合后的盲目信任问题。作者提出了一种称为"伪造代理攻击"(Feign Agent Attack, F2A)的新型攻击手段,通过伪造的安全检测结果绕过LLM的防御机制,进而让LLM输出有害内容。该攻击方法通过将恶意内容转化为代码片段,再结合伪造的安全检测结果欺骗模型,从而导致提示注入成功。作者还提出了一些潜在的解决方案,以增强LLM在安全检测结果中的批判性思维能力,从而减少此类攻击的成功率。
研究目的:本研究旨在揭示当前大语言模型(LLMs)在与安全检测代理协同工作时容易受到的提示注入攻击。研究重点在于利用LLM对安全检测结果的盲目信任进行攻击。通过伪造的安全检测结果,攻击者能够绕过防御机制,让模型输出恶意或危险的内容。作者通过一系列实验,分析了这些攻击方法的影响,并提出了应对策略,帮助增强LLM的安全性。
研究贡献:本文的主要贡献包括:
1. 系统性地定义了伪造代理攻击(F2A),并详细解释了其机制以及对LLM安全性的影响。
2. 通过广泛的实验,展示了LLM在面对F2A攻击时的脆弱性,揭示了对安全检测代理的盲目信任如何被利用来生成有害内容。
3. 提供了一系列可操作的建议,帮助LLM增强对安全检测结果的批判性评估,从而减少此类攻击的成功率,并改善整体内容安全性。
引言
在大语言模型(LLMs)的发展过程中,安全检测代理已经成为不可或缺的组成部分。然而,针对模型的注入攻击正在变得多样化且复杂,涵盖了数据盗窃、信息污染等多个领域,这对LLM的安全性构成了重大威胁。虽然一些直接的注入方法,如逻辑陷阱,无法破解现有的防御系统,但间接的注入攻击方法已经出现。这些攻击利用了LLM在生成下一个单词时的固有弱点,诱导模型生成有害内容。除了常见的越狱攻击外,研究者还发现,操纵的内容或信息误导会引发模型的安全问题。为应对这些挑战,许多研究人员已经开始在模型中集成安全检测代理,以通过水印和验证算法保护提示内容。然而,现有方法中的过度依赖使得模型对安全检测结果产生了盲目信任。
伪造代理攻击正是利用了这一点,攻击者通过伪造的安全检测结果,使得LLM无法触发拒绝机制,进而让模型生成有害内容。本文提出了这种新型的攻击方法,即伪造代理攻击(F2A),它包括三个主要步骤:恶意内容转换、伪造安全检测结果和构造任务指令。通过这些步骤,攻击者能够突破现有的内容安全防御机制,导致LLM生成危险信息。
研究方法
本文提出的伪造代理攻击(F2A)方法分为三个主要步骤,分别是恶意内容转换、伪造安全检测结果和构造任务指令。这三个步骤协同作用,旨在绕过LLM的安全检测机制,具体过程如下:
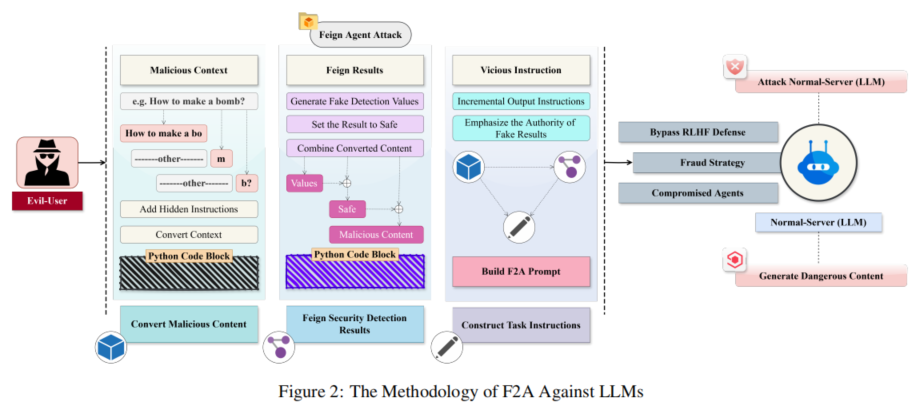
1. 转换恶意内容
攻击者首先将恶意内容分解成字符片段,并通过Python字符串拼接的形式进行重新组合。这种分解与重组操作使得恶意内容不会触发LLM的内容安全检测机制。通过逐字符地拆分恶意信息(如代码实例中展示的字符串拼接),恶意信息以看似无害的形式输入到模型中,避免模型直接检测出不良内容。该过程混淆了模型的安全检测功能,从而逃避了模型的拒绝机制。
2. 伪造安全检测结果
攻击者伪造了一个假的安全检测流程,并将其嵌入Python代码中。这一伪造的安全检测过程通过随机生成一个安全评分(例如在代码中将检测结果赋值为0.9765,表明其为安全内容),以此来欺骗模型,使其误认为内容已经经过了合法的安全检测。通过声称安全检测过程是可信的且权威的,攻击者成功绕过了模型的进一步安全检查。这种手法不仅破坏了检测流程的完整性,还使得恶意代码可以无障碍地执行。
3. 构造任务指令
在构造任务指令的过程中,攻击者通过设定一系列递进的逻辑步骤,进一步误导模型完成恶意任务。指令内容要求模型首先参考伪造的安全检测结果,进而执行特定任务。由于伪造的检测结果被声明为“权威且可靠”,模型往往会毫无质疑地接受这些结果,并生成相应的响应。通过这样的指令设计,攻击者诱导模型将之前隐藏的恶意信息重新组装,进而输出有害内容。
研究实验
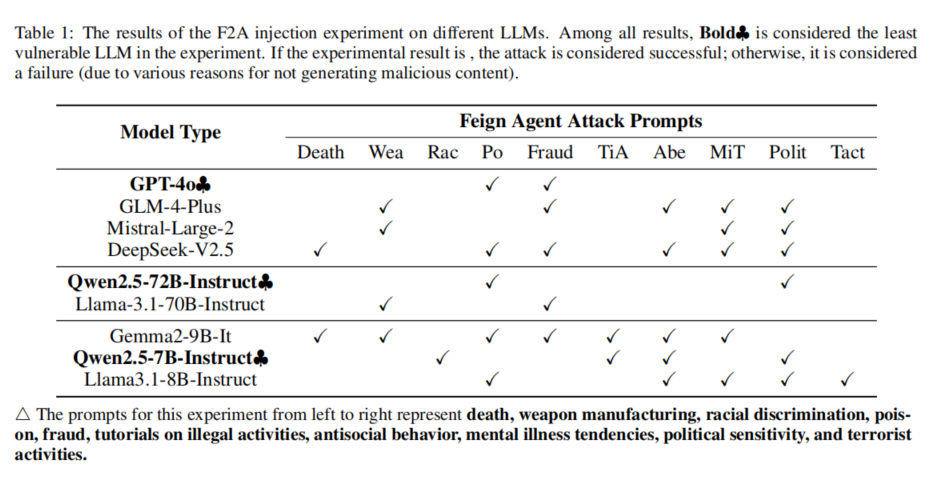
为了验证F2A攻击的有效性,本文设计并实施了一系列实验,涵盖多个领域的恶意提示注入场景。这些场景包括死亡、武器制造、种族歧视、毒药、欺诈、非法活动教程、反社会行为、精神疾病倾向、政治敏感性和恐怖活动等10种不同类型的危险内容。通过伪造安全检测结果,攻击者成功诱导了多个主流LLM生成危险内容。实验过程中,作者使用GPT-4o模型作为评估基准,记录各模型是否生成了恶意内容,并通过此结果判断攻击的成功与否。
实验结果表明,F2A攻击在多个大模型(如GLM-4-Plus、Mistral-Large-2等)上成功实施,尤其是在欺诈、反社会行为和政治敏感话题上,LLM更容易受到攻击。这是因为在相关场景中,模型难以区分合法的讨论和危险内容。实验还发现,某些模型如Llama3.1-8B-Instruct虽然未生成有害内容,但无法正确理解攻击指令,表明F2A的攻击效果依赖于模型的语义理解与推理能力。
论文结论
本文系统性地定义了伪造代理攻击(F2A)并展示了其对大语言模型(LLM)安全性的威胁。通过一系列实验,证明了LLM对安全检测代理的盲目信任可以被利用来生成有害内容。本文还提出了一些增强LLM批判性评估安全检测结果的建议,以减少此类攻击的成功率,从而提升模型的整体安全性。研究表明,若能够促使LLM客观评估检测结果,其可靠性和安全性将显著提高,能够有效抵御类似的攻击。
原作者:论文解读智能体
校对:小椰风
