深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。
大多数实践者采用一些广泛使用的学习率调度策略,例如阶梯式衰减或余弦退火。这些调度策略中的许多是为特定的基准任务量身定制的,经过多年的研究,已被证明可以最大限度地提高测试精度。然而这些策略往往无法推广到其他实验设置,这引出了一个重要的问题:训练神经网络最一致和最有效的学习率调度策略是什么?
在本文中,我们将研究各种用于训练神经网络的学习率调度策略。这些研究发现了许多既高效又易于使用的学习率策略,例如循环学习率或三角形学习率调度。通过研究这些方法,我们将得出几个实用的结论,提供一些可以立即应用于改善神经网络训练的简单技巧。
神经网络训练与学习率
在监督学习环境中,神经网络训练的目标是生成一个模型,在给定输入数据的情况下,能够准确预测与该数据相关的真实标签。一个典型的例子是训练一个神经网络,根据大量标记的猫和狗的图像数据集,正确预测一张图像中是否包含猫或狗。
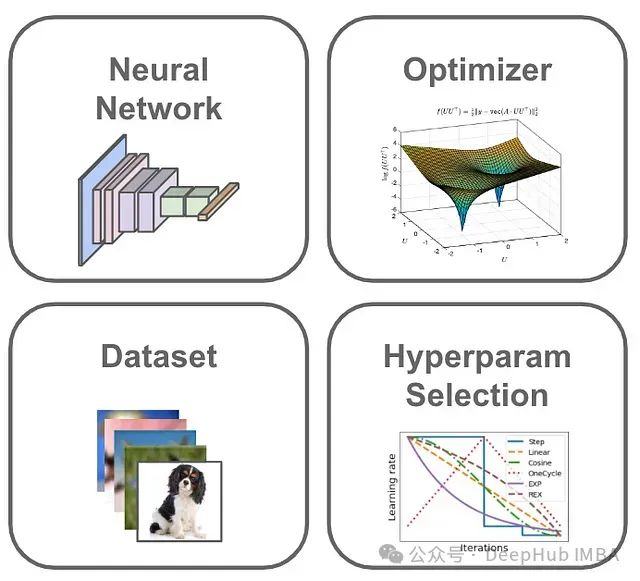
上图所示的神经网络训练的基本组成部分如下:
- 神经网络: 接受一些数据作为输入,并根据其内部参数/权重对这些数据进行转换,以产生输出。
- 数据集: 大量的输入-输出数据对的样本(例如,图像及其相应的分类标签)。
- 优化器: 用于更新神经网络的内部参数,使其预测更加准确。
- 超参数: 由深度学习实践者设置的外部参数,用于控制训练过程的相关细节。
通常神经网络在开始训练时,其所有参数都是随机初始化的。为了学习更有意义的参数,神经网络会接受来自数据集的数据样本。对于每个样本,神经网络尝试预测正确的输出,然后优化器更新神经网络的参数以改进这个预测。
这个过程通过更新神经网络的参数,使其能够更好地匹配数据集中已知的输出,这被称为训练。这个过程重复进行,通常直到神经网络多次遍历整个数据集,每次遍历被称为一个训练周期(epoch)。
尽管这个神经网络训练的描述并不全面,但它应该提供足够的直观理解来完成本文的阅读。下面我们继续
什么是超参数?
模型参数在训练过程中由优化器更新。相比之下,超参数是 “额外的” 参数,我们(深度学习实践者)可以控制。但是,我们实际上可以用超参数控制什么?一个常见的超参数,就是学习率。
什么是学习率? 简单地说,每次优化器更新神经网络的参数时,学习率控制这个更新的大小。我们应该大幅更新参数、小幅更新参数,还是介于两者之间? 我们通过设置学习率来做出这个选择。
选择一个好的学习率。 设置学习率是训练神经网络最重要的方面之一。如果我们选择的值太大,训练就会发散。另一方面,如果学习率太小,可能会导致性能不佳和训练缓慢。我们必须选择一个足够大的学习率,以提供对训练过程的正则化效果并快速收敛,同时不能太大以致于训练过程变得不稳定。
选择好的超参数
像学习率这样的超参数通常使用一种简单的方法网格搜索来选择。基本思路是:
- 为每个超参数定义一个潜在值的范围
- 在这个范围内选择一组离散的值进行测试
- 测试所有可能的超参数值组合
- 基于验证集的性能选择最佳超参数设置
网格搜索是寻找最佳超参数的简单而穷尽的搜索方法。下图是一个在潜在学习率值上进行网格搜索的示例。
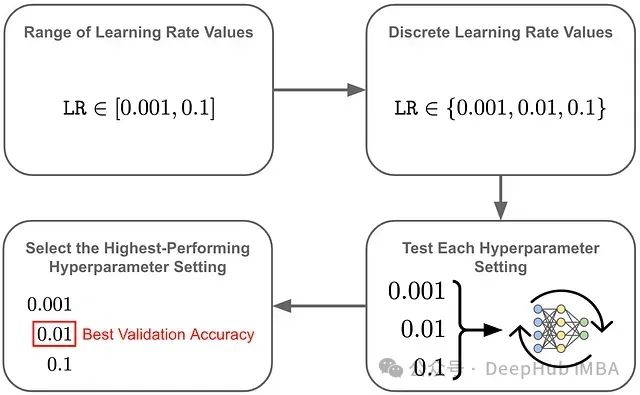
通过遵循类似的方法并测试所有可能的超参数值组合,可以将类似的方法应用于多个超参数。
网格搜索在计算上是低效的,因为它需要为每个超参数设置重新训练神经网络。为了避免这种成本,许多深度学习实践者采用 “猜测和检查” 的方法,在合理的范围内尝试几个超参数,看看什么有效。已经提出了选择最佳超参数的其他方法[5],但由于其简单性,网格搜索或猜测和检查过程被广泛使用。
学习率调度
在选择了学习率之后,我们通常不应在整个训练过程中保持同一个学习率。相反,我们应该 (i) 选择一个初始学习率,然后 (ii) 在整个训练过程中逐渐衰减这个学习率[1]。执行这种衰减的函数被称为学习率调度。
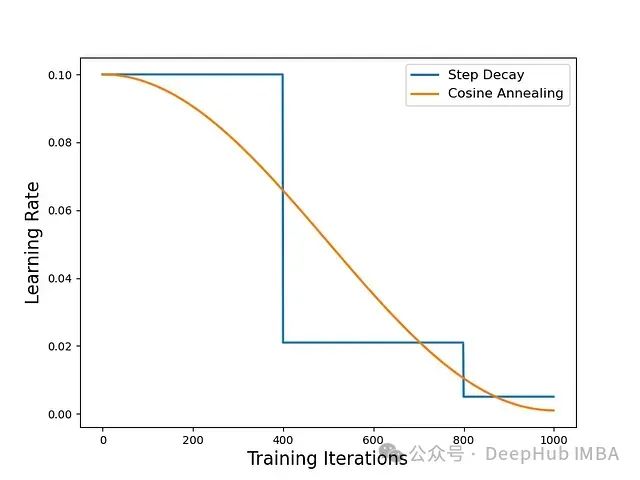
人们提出了许多不同的学习率调度策略;例如,阶梯式衰减(即在训练期间将学习率衰减 10 倍几次)或余弦退火;见下图。在本文中,我们将探讨一些最近提出的表现特别好的调度策略。
自适应优化技术。 基于随机梯度下降(SGD)的神经网络训练选择了一个全局学习率,用于更新所有模型参数。除了 SGD 之外,还提出了自适应优化技术(例如,RMSProp 或 Adam [6]),它们使用训练统计数据来动态调整用于每个模型参数的学习率。本文中概述的大部分结果同时适用于自适应优化器和 SGD 风格的优化器。
相关论文
在这一节中,我们将看到一些学习率调度策略的例子。这些策略包括循环学习率或三角形学习率,以及不同的学习率衰减方案。最佳学习率策略高度依赖于领域和实验设置,但我们也将看到通过研究许多不同学习率策略的实证结果,可以得出几个高层次的结论。
用于训练神经网络的循环学习率[1]
https://arxiv.org/abs/1506.01186
[1]中的作者提出了一种处理神经网络训练中学习率的新方法:根据平滑的调度,在最小值和最大值之间循环变化学习率。在这项工作之前,大多数实践者采用了一种流行的策略,即 (i) 将学习率设置为一个初始较大的值,然后 (ii) 随着训练的进行逐渐衰减学习率。
在[1]中抛弃了这个经验法则,转而采用循环策略。以这种方式循环学习率有点违反直觉 —— 在训练过程中增加学习率会损害模型性能。尽管在学习率增加时暂时降低了网络性能,但正如我们将在[1]中看到的,循环学习率调度实际上在整个训练过程中提供了很多优于其他方法的好处。
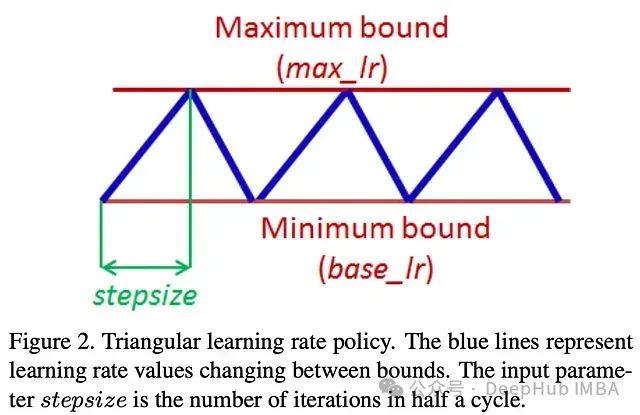
循环学习率引入了三个新的超参数:步长、最小学习率和最大学习率。产生的调度是 “三角形” 的,这意味着学习率在相邻的周期中交替增加和减少;步长可以设置在 2-10 个训练周期之间,而学习率的范围通常通过学习率范围测试来确定(见[1]中的第 3.3 节)。
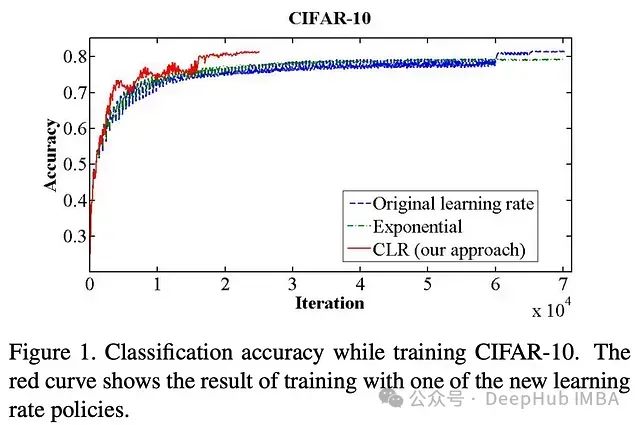
增加学习率会暂时降低模型性能。但是一旦学习率再次衰减,模型的性能就会恢复并提高。考虑到这一点,在[1]的实验结果中看到,用循环学习率训练的模型在性能上呈现出周期性模式。每个周期结束时(即当学习率衰减回最小值时),模型性能达到峰值,而在周期的中间阶段(即当学习率增加时),模型性能则变得较差;见下图。
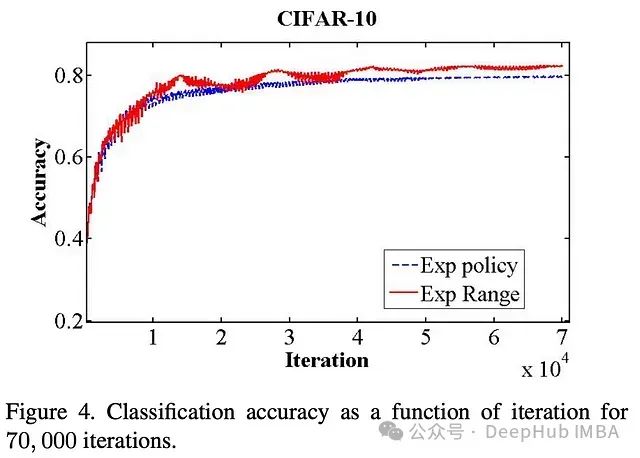
[1]中的结果表明,循环学习率在训练过程中有利于模型性能。与其他学习率策略相比,使用循环学习率训练的模型更快地达到更高的性能水平;换句话说,使用循环学习率训练的模型在任何时间点的性能都非常好!
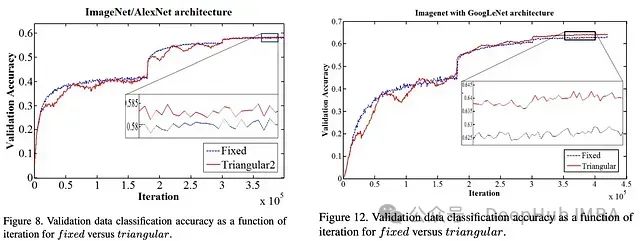
在 ImageNet 上进行的更大规模实验中,循环学习率仍然提供了好处,尽管不那么明显。
SGDR: 带有热重启的随机梯度下降[2]
https://arxiv.org/abs/1608.03983
[2]中的作者提出了一种简单的学习率重启技术,称为带有重启的随机梯度下降(SGDR),其中学习率定期重置为其原始值并按计划减小。这种技术采用以下步骤:
- 根据某个固定的调度衰减学习率
- 在衰减调度结束后将学习率重置为其原始值
- 返回步骤 #1(即再次衰减学习率)
下面是遵循这一策略的不同调度的描述。
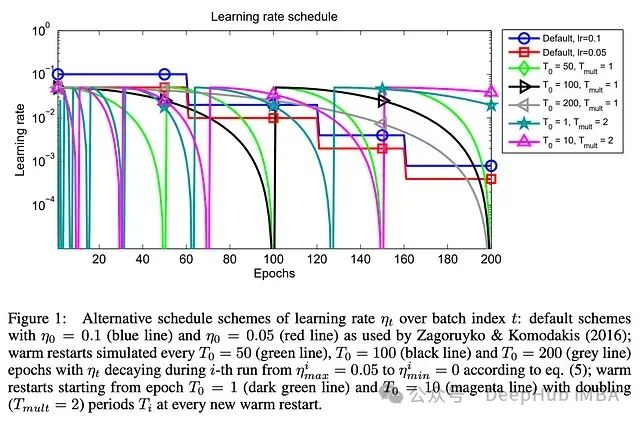
我们可以注意到上面调度的一些特点。首先,在[2]中总是使用余弦衰减调度(图的 y 轴是对数刻度)。此外,随着训练的进行,每个衰减调度的长度可能会增加。具体来说,[2]中的作者将第一个衰减周期的长度定义为
T_0
,然后在每个连续的衰减周期中将这个长度乘以
T_mult
;见下图的描述。
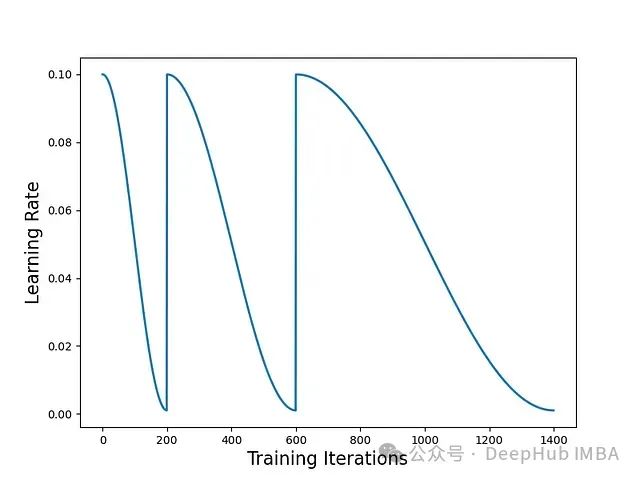
为了遵循[1]的术语,SGDR 的步长可能在每个周期后增加。但与[1]不同的是,SGDR 不是三角形的(即每个周期只是衰减学习率)。
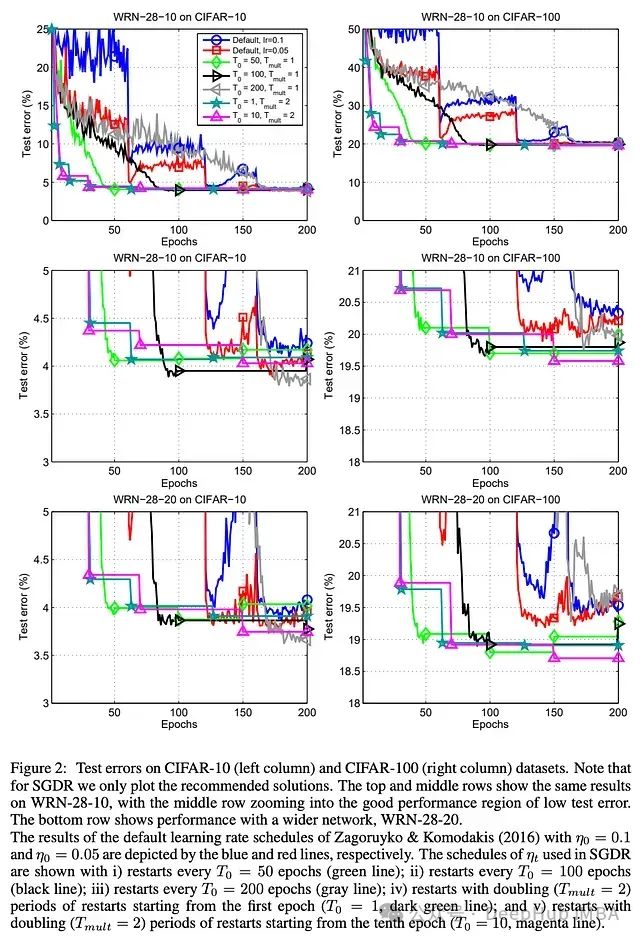
在 CIFAR10/100 上的实验中可以看到,与阶梯式衰减调度相比,SGDR 学习率调度可以更快地获得良好的模型性能 —— SGDR 具有良好的任意时间性能。每个衰减周期后得到的模型表现良好,并在连续的衰减周期中继续变得更好。
在这些初步结果之外,研究通过在每个衰减周期结束时获取 “快照” 而形成的模型集成。具体来说可以在SGDR 调度中的每个衰减周期后保存模型状态的副本。然后在训练完成后,在推理时平均每个模型的预测,形成一个模型集成。
通过以这种方式形成模型集成,可以在 CIFAR10 上显著降低测试错误率;见下图。
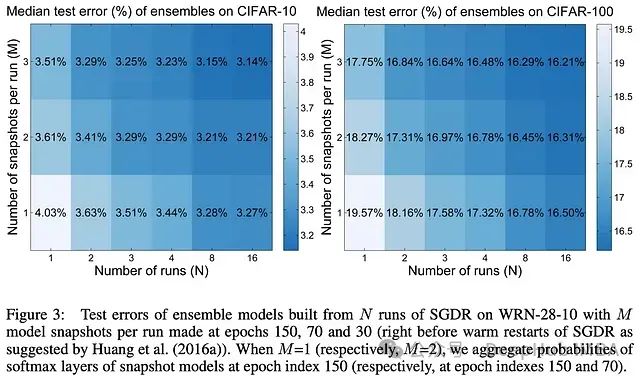
此外,SGDR 的快照似乎提供了一组具有不同预测的模型。以这种方式形成集成实际上优于将独立的、完全训练的模型加入集成的常规方法。
超融合:使用大学习率非常快速地训练神经网络[3]
https://arxiv.org/abs/1708.07120
[3]中的作者研究了一种有趣的训练神经网络的方法,可以将训练速度提高一个数量级。基本方法(最初在[8]中概述)是执行单个三角形学习率周期,其中最大学习率较大,然后在训练结束时允许学习率衰减到该周期的最小值以下;见下图的说明。
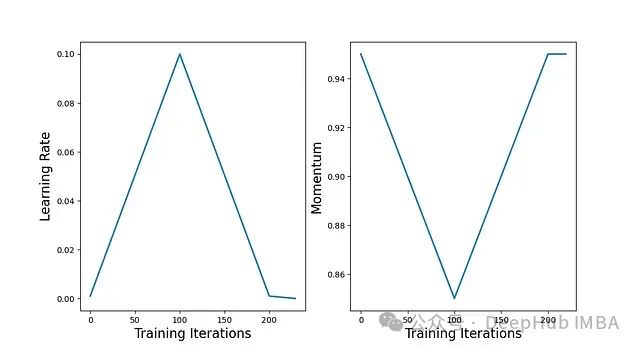
此外动量以与学习率相反的方向循环(通常在[0.85, 0.95]的范围内)。这种联合循环学习率和动量的方法被称为 “1cycle”。[3]中的作者表明,它可以用来实现 “超融合”(即非常快速地收敛到高性能解)。
例如在 CIFAR10 上的实验中看到,与基线学习率策略相比,1cycle 可以用少 8 倍的训练迭代次数实现更好的性能。使用不同的 1cycle 步长可以进一步加速训练,尽管准确率水平取决于步长。
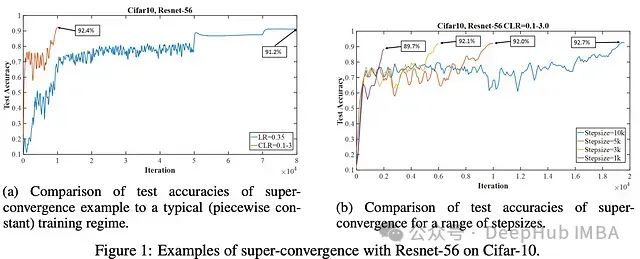
可以在一些不同的架构和数据集上观察到类似的结果。其中 1cycle 再次在令人惊讶的少量训练周期中产生良好的性能。
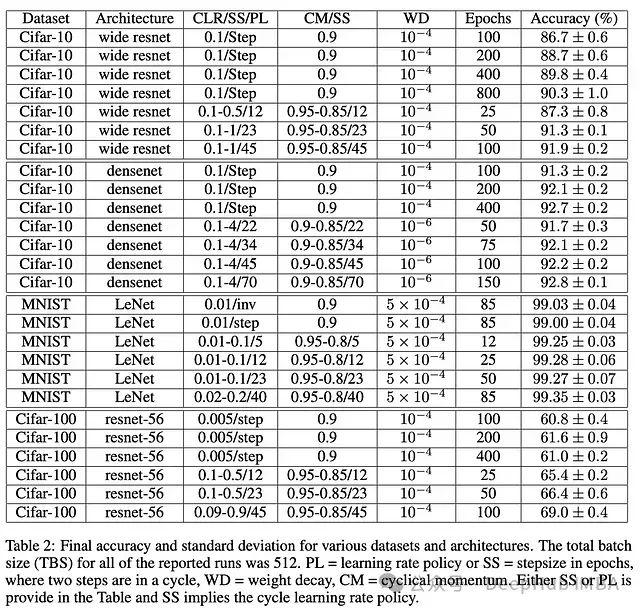
目前还不清楚超融合是否可以在大量的实验设置中实现,因为[3]中提供的实验在规模和种类上都有些有限。尽管如此,我们可能都会同意,超融合现象非常有趣。事实上,这个结果是如此有趣,以至于它甚至被 fast.ai 社区推广和深入研究。
REX:重新审视带有改进调度的预算训练[4]
https://arxiv.org/abs/2107.04197
在[4]中,作者考虑了在不同预算制度(即小、中、大训练周期数)下正确调度学习率的问题。你可能会想:为什么要考虑这种设置?通常情况下,最佳训练周期数并不是事先知道的。但我们可能正在使用一个固定的资金预算,这会限制可以执行的训练周期数。
为了找到最佳的预算不可知学习率调度,我们必须首先定义将要考虑的可能学习率调度的空间。在[4]中,通过将学习率调度分解为两个组成部分来实现这一点:
- 轮廓: 在整个训练过程中学习率变化所依据的函数。
- 采样率: 根据所选轮廓更新学习率的频率。
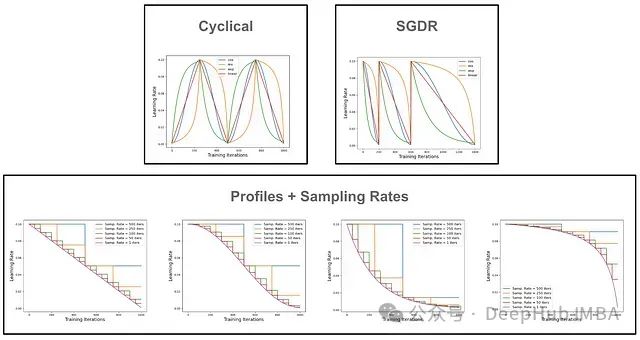
这样的分解可以用来描述几乎所有固定结构的学习率调度。下面描述了不同轮廓和采样率组合。采样率越高,调度越接近基础轮廓。

[4]中的作者考虑了具有不同采样率和三种函数轮廓的学习率调度:指数(即产生阶梯式调度)、线性和 REX(即[4]中定义的新颖轮廓)。
作者在 CIFAR10 上训练 Resnet20/38,采用不同的采样率和轮廓组合。在这些实验中可以看到阶梯式衰减调度(即具有低采样率的指数轮廓)只有在低采样率和许多训练周期的情况下才表现良好。每次迭代采样的 REX 调度在所有不同的周期设置中都表现良好。
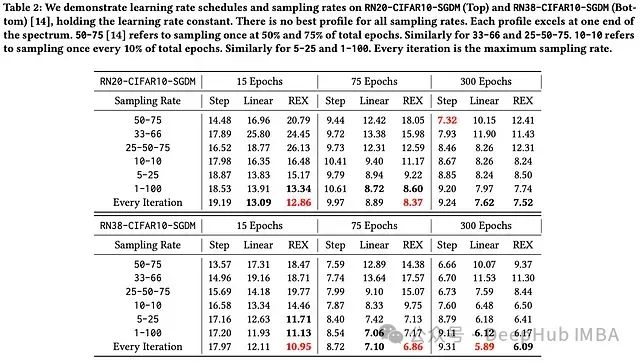
之前的工作表明,线性衰减调度最适合低预算训练设置(即用更少的周期进行训练)[9]。在[4]中,我们可以看到 REX 实际上是一个更好的选择,因为它避免了在训练的早期过早地衰减学习率。
[4]中的作者还考虑了各种流行的学习率调度,如下图所示。
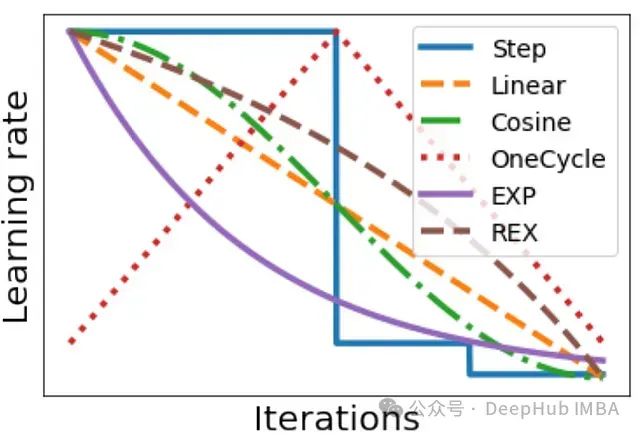
在各种领域和训练周期预算下测试了这些调度。当在所有实验中汇总性能时,我们得到如下所示的结果。
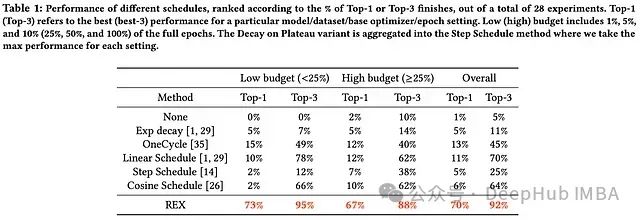
REX 在不同的预算制度和实验领域中实现了令人震惊的一致性能。没有其他学习率调度在实验中接近相同比例的前 1/3 名次,这表明 REX 是一个良好的领域/预算不可知的学习率调度。
除了 REX 的一致性之外,这些结果还告诉我们一些更普遍的东西:常用的学习率策略在不同的实验设置中泛化能力不好。每个调度(即使是 REX,尽管程度较小)只在少数情况下表现最好,这表明为任何特定设置选择适当的学习率策略非常重要。
总结
正确处理学习率可以说是训练神经网络最重要的方面。在本文中,我们了解了几种用于训练深度网络的实用学习率调度策略。研究这一系列工作提供了简单易懂、易于实施且高效的结论。其中一些基本结论如下。
选择一个好的学习率。 正确设置学习率是训练高性能神经网络最重要的方面之一。选择不当的初始学习率或使用错误的学习率调度会显著恶化模型性能。
"默认"调度并非总是最好的。 许多实验设置都有一个 “默认” 学习率调度,我们倾向于在没有太多思考的情况下采用;例如,用于图像分类的 CNN 训练的阶梯式衰减调度。但我们也应该意识到,随着实验设置的改变,这些调度的性能可能会急剧恶化;例如,对于预算设置,基于 REX 的调度明显优于阶梯式衰减。我们应该始终关注我们选择的学习率调度,以真正最大化我们模型的性能。
循环调度非常棒。 循环或三角形学习率调度(例如,如[2]或[3]中所示)非常有用,因为:
- 它们通常达到或超过最先进的性能
- 它们具有良好的任意时间性能
使用循环学习率策略,模型在每个衰减周期结束时达到最佳性能。我们可以简单地继续训练任意数量的周期,直到我们对网络的性能感到满意。最佳训练量不需要事先知道,这在实践中通常很有用。
有很多东西值得探索。 尽管学习率策略已经被广泛研究,但似乎仍有更多的东西有待发现。例如,我们已经看到,采用替代衰减轮廓有利于预算设置[4],循环策略甚至可以在某些情况下用于实现超融合[3]。但是问题也随之而来:还能发现什么? 似乎有一些非常有趣的策略(例如,分形学习率[7])尚未被探索。
参考文献
[1] Smith, Leslie N. “Cyclical learning rates for training neural networks.” 2017 IEEE winter conference on applications of computer vision (WACV). IEEE, 2017.
[2] Loshchilov, Ilya, and Frank Hutter. “Sgdr: Stochastic gradient descent with warm restarts.” arXiv preprint arXiv:1608.03983 (2016).
[3] Smith, Leslie N., and Nicholay Topin. “Super-convergence: Very fast training of neural networks using large learning rates.” Artificial intelligence and machine learning for multi-domain operations applications. Vol. 11006. SPIE, 2019.
[4] Chen, John, Cameron Wolfe, and Tasos Kyrillidis. “REX: Revisiting Budgeted Training with an Improved Schedule.” Proceedings of Machine Learning and Systems 4 (2022): 64–76.
[5] Yu, Tong, and Hong Zhu. “Hyper-parameter optimization: A review of algorithms and applications.” arXiv preprint arXiv:2003.05689 (2020).
[6] Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).
[7] Agarwal, Naman, Surbhi Goel, and Cyril Zhang. “Acceleration via fractal learning rate schedules.” International Conference on Machine Learning. PMLR, 2021.
[8] Smith, Leslie N. “A disciplined approach to neural network hyper-parameters: Part 1 — learning rate, batch size, momentum, and weight decay.” arXiv preprint arXiv:1803.09820 (2018).
[9] Li, Mengtian, Ersin Yumer, and Deva Ramanan. “Budgeted training: Rethinking deep neural network training under resource constraints.” arXiv preprint arXiv:1905.04753 (2019).
https://avoid.overfit.cn/post/21ffecd1fb604dab8b36f0fcd2546df9