目录
1、认识Python
2、环境与工具
2.1 python环境
2.2 Visual Studio Code编译
3、统计文本文件中单词频率
3.1 代码构思
3.2 代码示例
3.3 运行结果
4、总结
1、认识Python
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字或标点符号,它具有比其他语言更有特色的语法结构。

2、环境与工具
2.1 python环境
在Windows上使用命令行窗口查看所安装的python版本
python --version
2.2 Visual Studio Code编译
Visual Studio Code是一款由微软开发且跨平台的免费源代码编辑器。该软件以扩展的方式支持语法高亮、代码自动补全、代码重构功能,并且内置了命令行工具和Git 版本控制系统。

3、统计文本文件中单词频率
3.1 代码构思
对文本文件一行一行的进行遍历,在通过列表生成式吧每一个单词取出放在变量中,内层循环统计每一个单词出现的次数,再对次数进行统计排序,最后函数对排好序的字典按传入的参数值进行切片并返回。注意要在代码目录下新建一个文本文件“test.txt”
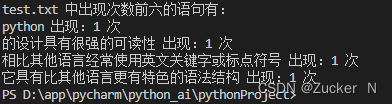
3.2 代码示例
import re# 定义一个类
class CounterWord:def __init__(self, file_name):# 设置要统计单词的文件名self.filename = file_name# 初始化字典,用来保存单词出现的次数self.dict_count = {}# 定义一个统计函数def count_word(self):try:with open(self.filename, 'r', encoding='utf-8') as f:# 循环读取每一行for line in f:words = [s.lower() for s in re.findall(r'\w+', line)]# 统计单词出现的次数for word in words:self.dict_count[word] = self.dict_count.get(word, 0) + 1except FileNotFoundError:print(f"文件 {self.filename} 未找到。")except Exception as e:print(f"读取文件时发生错误:{e}")# 取出现次数在num前的单词def top_number(self, num):return sorted(self.dict_count.items(), key=lambda item: item[1], reverse=True)[:num]if __name__ == '__main__':counter_obj = CounterWord('./part2/test.txt')counter_obj.count_word()top_num_6 = counter_obj.top_number(6)print('test.txt 中出现次数前六的单词有:')for word, count in top_num_6:print(f"{word} 出现:{count} 次")3.3 运行结果
4、总结
该代码可以用作文本内容检查,检查高频率用语。