
Mistral AI 开源了 Pixtral 12B 多模态 LLM。具有自然场景理解,代码生成,图像转代码,图像理解,多图指令跟随,图表理解与分析以及复杂图形推理等多项能力。从效果演示来看模型的能力很强,其中对中文能力的理解也很好。已经开放了模型下载地址和模型试用地址,大家可以去体验一下。

Pixtral 12B主要特点
-
Mistral Nemo 12B 的直接替代品;
-
从头开始训练的新型 400M 参数视觉编码器;
-
搭配基于 Mistral Nemo 的 12B 多模态解码器;
-
能处理可变的图像尺寸和纵横比;
-
支持128k上下文窗口中的多个图像。
Pixtral 12B 简介
原生多模式,使用交错图像和文本数据进行训练 在多模式任务中表现出色,擅长遵循指令 在纯文本基准测试中保持最佳性能 建筑学: 从头开始训练的新型 400M 参数视觉编码器 基于 Mistral Nemo 的 12B 参数多模态解码器 支持可变的图像尺寸和纵横比 支持 128k 个 token 的长上下文窗口中的多个图像 使用: 许可证:Apache 2.0 在 La Plateforme或Le Chat 上尝试 Pixtral 经过训练可以理解自然图像和文档,在 MMMU 推理基准测试中达到 52.5%,超过了许多大型模型。该模型在图表和图形理解、文档问答、多模态推理和指令遵循等任务中表现出色。Pixtral 能够以自然分辨率和宽高比摄取图像,让用户可以灵活地使用标记数量来处理图像。Pixtral 还能够在其 128K 标记的长上下文窗口中处理任意数量的图像。与之前的开源模型不同,Pixtral 不会在文本基准测试性能上妥协,以在多模态任务中表现出色。
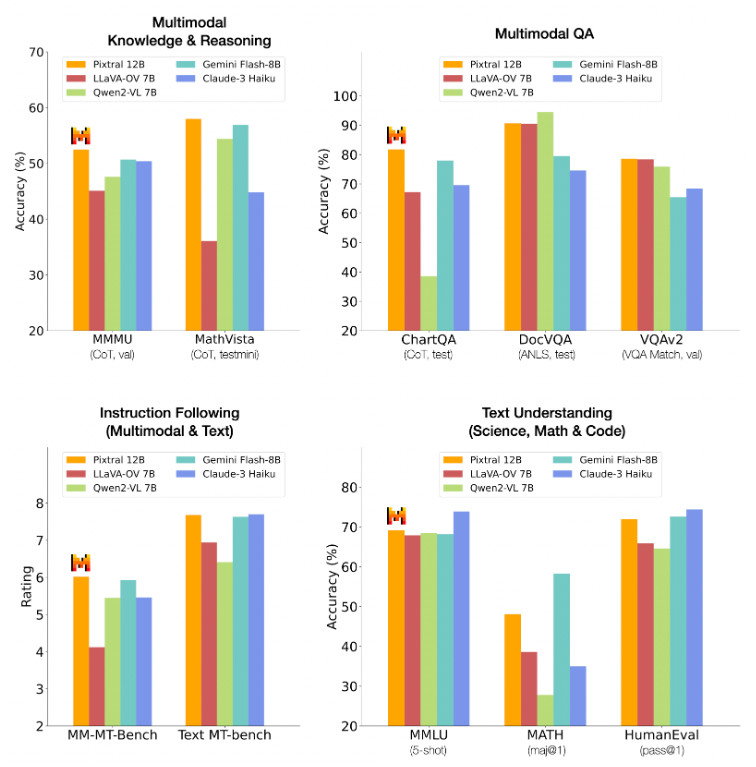
表现
Pixtral 经过训练,可以替代Mistral Nemo 12B。它与现有开源模型的主要区别在于,它提供了一流的多模式推理能力, 同时又不影响关键的文本功能,例如指令跟踪、编码和数学。
评估方案
通过相同的评估工具重新评估了一系列开放和封闭模型。对于每个数据集,我们选择提示以便能够重现领先的多模态模型(GPT-4o 和 Claude-3.5-Sonnet)的结果。然后使用相同的提示评估所有模型。总体而言,Pixtral 的表现大大优于其规模范围内的所有开放模型,并且在许多情况下优于 Claude 3 Haiku 等封闭模型。在多模态基准测试中,Pixtral 甚至优于或匹敌 LLaVa OneVision 72B 等更大的模型的性能。所有提示都将开源。

遵循指令
与其他开放的多模态模型相比,Pixtral 在多模态和纯文本指令跟踪方面表现尤为出色。它在指令跟踪方面的表现大大优于 Qwen2-VL 7B、LLaVa-OneVision 7B 和 Phi-3.5 Vision,在文本IF-Eval 和MT-Bench方面比最接近的 OSS 模型提高了 20%。为了进一步评估这种多模态用例的能力,我们创建了这些基准的多模态版本:MM-IF-Eval和MM-MT-Bench。Pixtral在多模态指令跟踪基准测试方面的表现也优于开源替代方案。我们将向社区开源MM-MT-Bench。
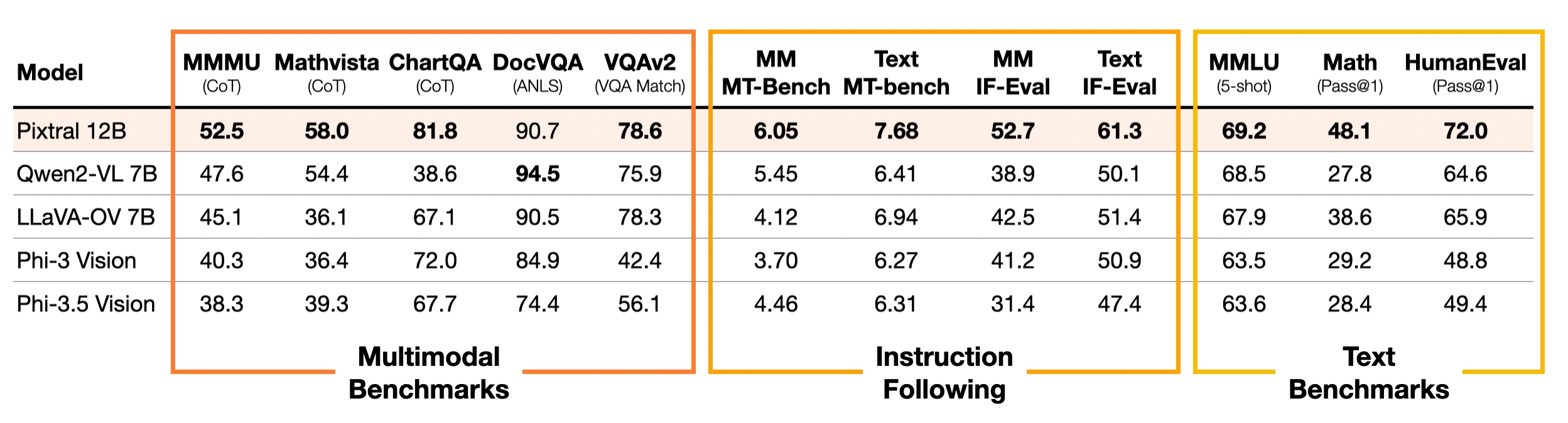
Pixtral 的性能与开放多模态模型相比。所有模型都通过相同的评估工具和相同的提示进行基准测试。
模型结构
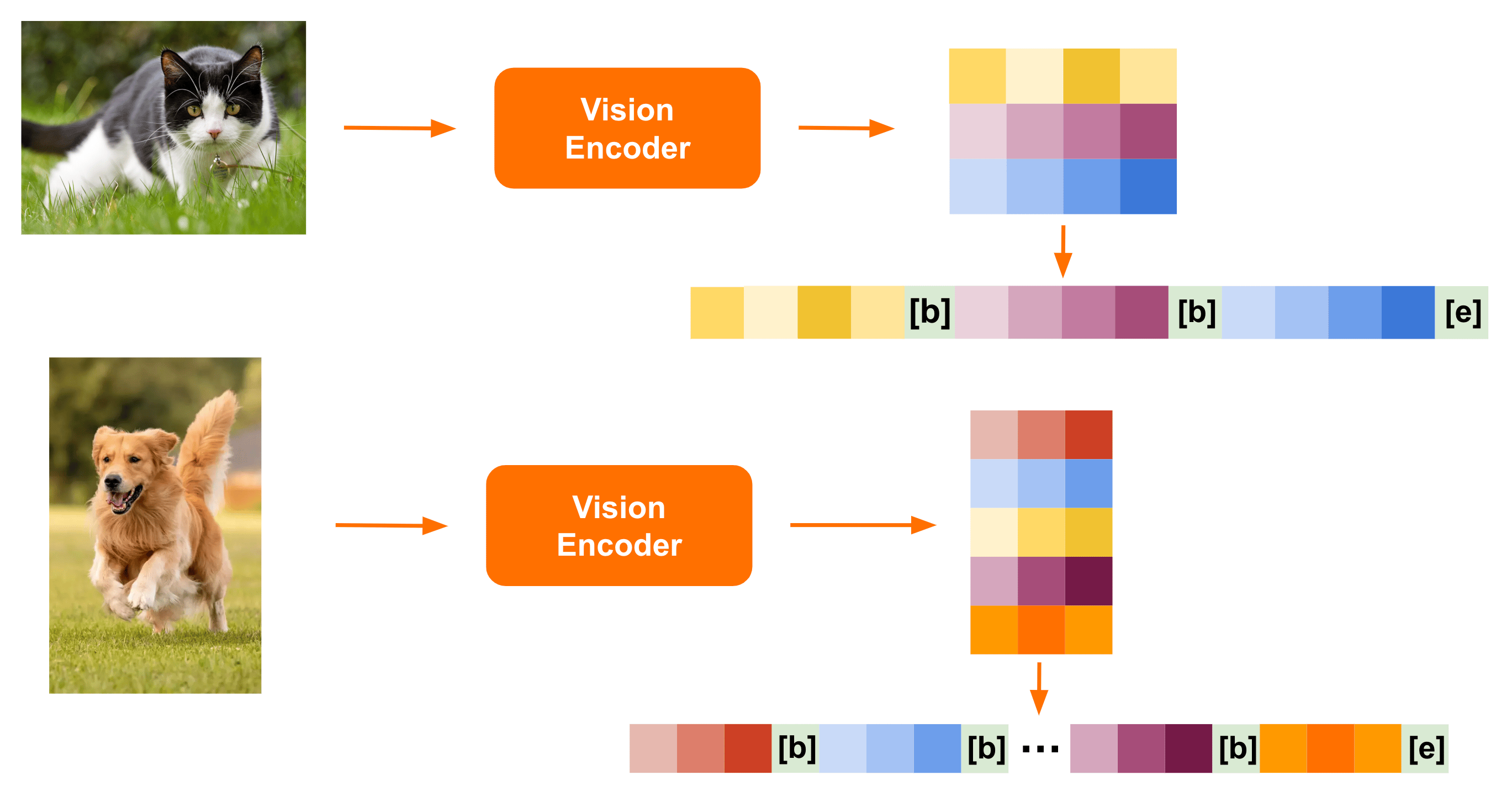
可变图像大小: Pixtral 旨在优化速度和性能。我们训练了一种新的视觉编码器,它原生支持可变图像大小:
-
我们只需将图像以其原始分辨率和宽高比传递到视觉编码器,即可将其转换为图像中每个 16x16 块的图像标记
-
然后将这些标记展平以创建一个序列,并[IMG BREAK]在行[IMG END]之间和图像末尾添加标记。
-
[IMG BREAK]标记让模型能够用相同数量的标记来区分不同纵横比的图像。 通过这种方式,Pixtral 可以用来准确理解高分辨率的复杂图表、图表和文档,同时为图标、剪贴画和方程式等小图像提供快速的推理速度。
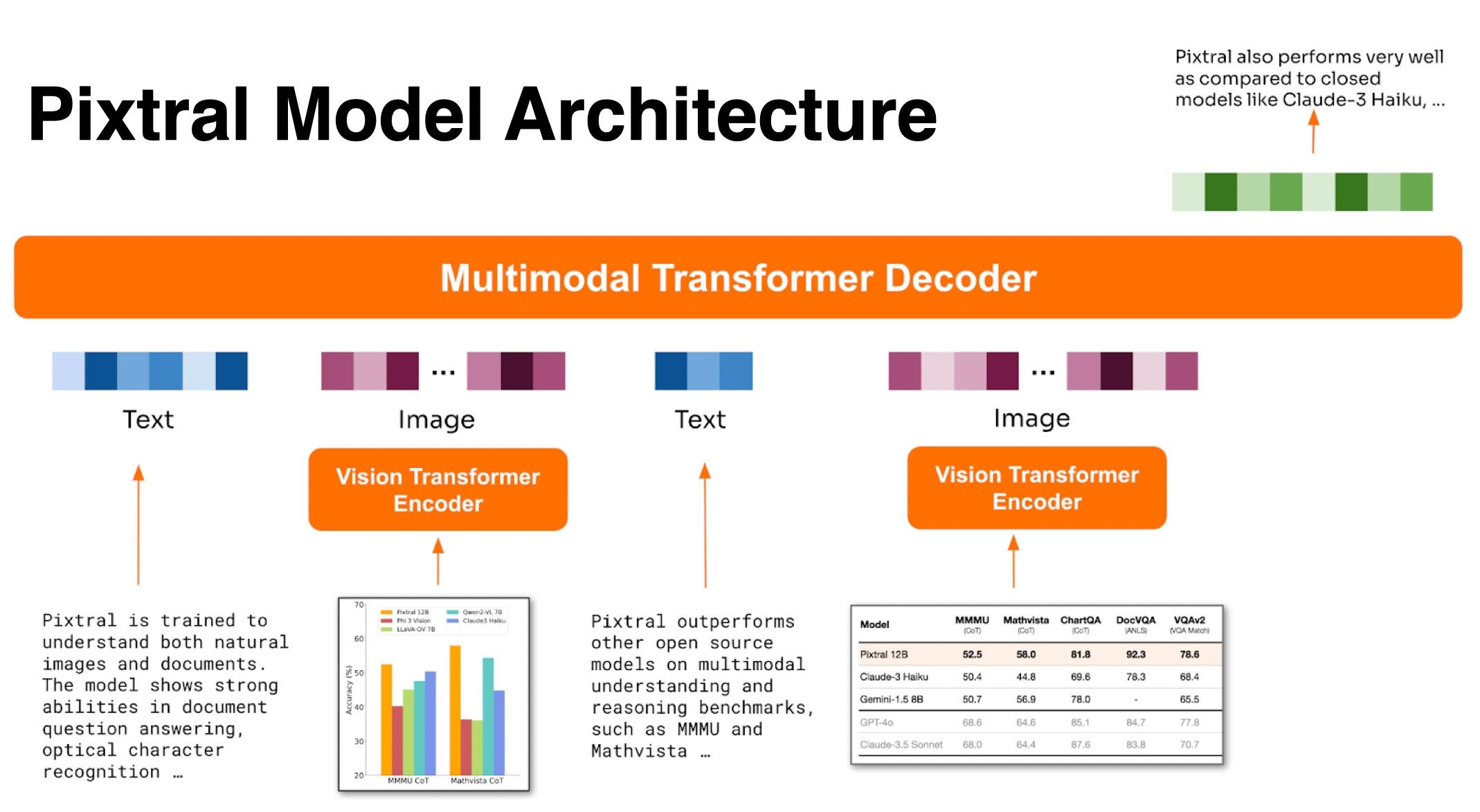
最终架构: Pixtral 有两个组件:Vision Encoder(用于对图像进行标记)和 Multimodal Transformer Decoder(用于根据给定的文本和图像序列预测下一个文本标记)。该模型经过训练,可以在交错的图像和文本数据上预测下一个文本标记。这种架构允许 Pixtral 在其 128K 个标记的大型上下文窗口中处理任意数量、任意大小的图像。
定性示例
复杂图形推理
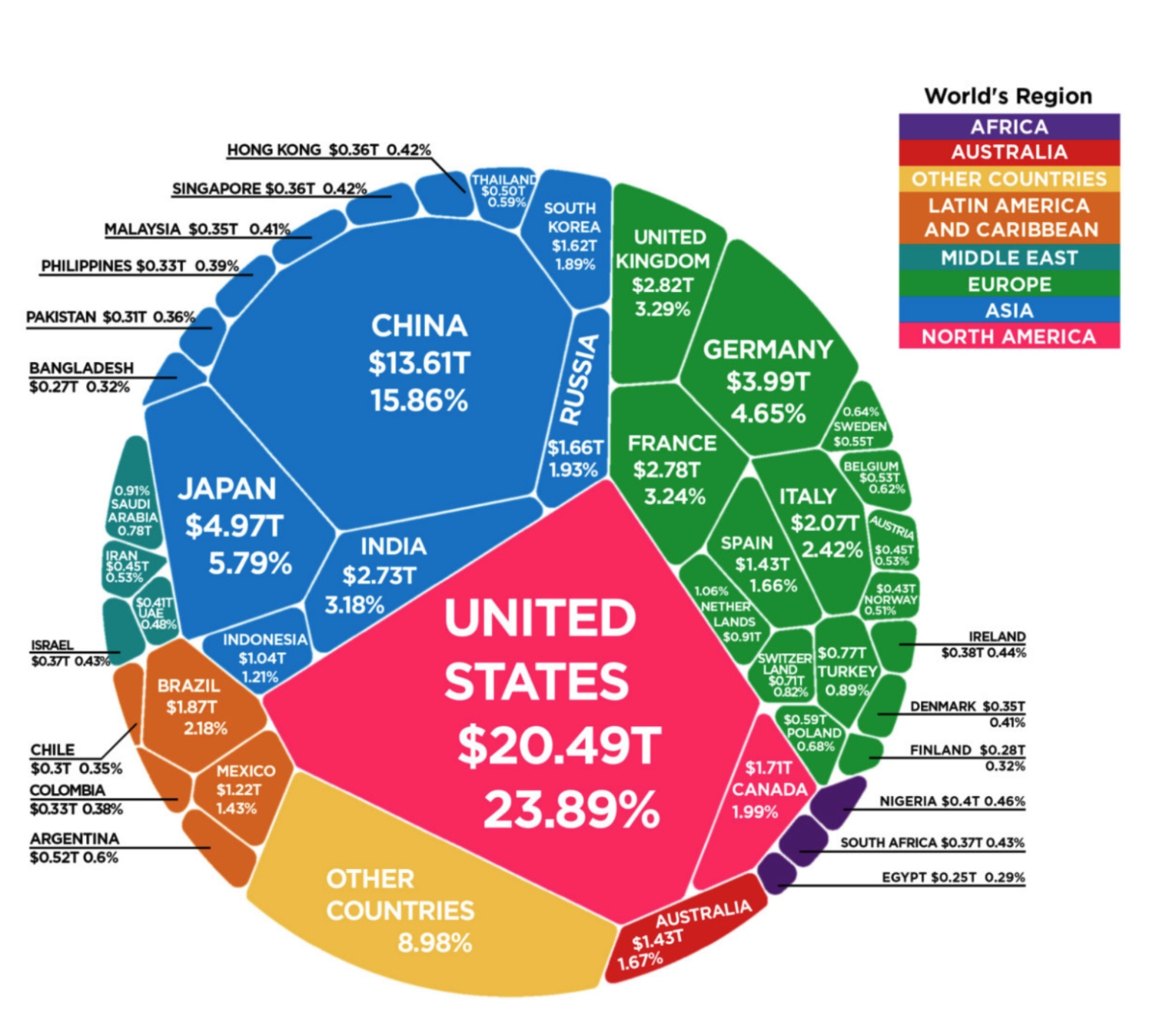
prompt:列出欧洲 GDP 最高的 5 个国家
回复:根据图片,欧洲 GDP 最高的 5 个国家是:
-
德国,国内生产总值:3.99万亿美元,比例:4.65%
-
英国,国内生产总值:2.82万亿美元,百分比:3.29%
-
法国,国内生产总值:2.78万亿美元,百分比:3.24%
-
意大利,国内生产总值:2.07万亿美元,百分比:2.42%
-
西班牙,国内生产总值:1.43万亿美元,比例:1.66% 这些国家在图表上以绿色突出显示。
图表理解与分析
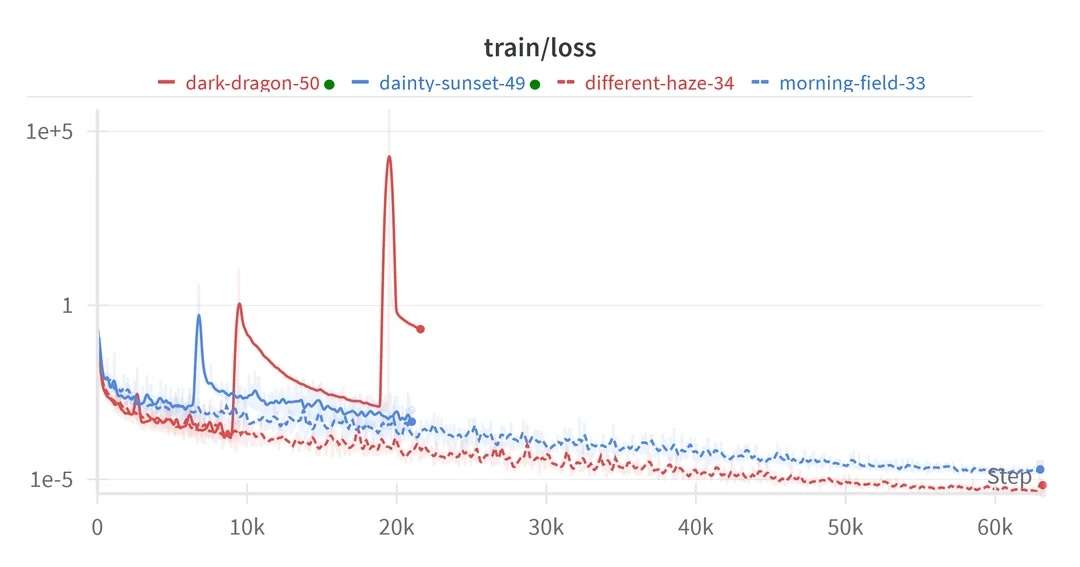
prompts:训练情况什么时候开始变糟的?
回复:该图是一个名为“训练/损失”的线图,显示了四个不同模型的训练损失:dark-dragon-50、dainty-sunset-49、different-haze-34 和 morning-field-33。x 轴表示步骤,范围从 0 到 60k,y 轴表示从 1e-5 到 1e+5 的对数刻度上的损失。
要确定 dark-dragon-50 模型何时开始出现问题,我们需要查看代表该模型的红线。最初,损失减少,表明模型正在有效学习。然而,在 10k 步左右,损失开始大幅飙升。这个峰值表明模型的性能正在恶化。损失继续飙升和波动,达到非常高的值,这表明模型没有有效学习,很可能过度拟合或遇到其他问题。
因此,dark-dragon-50 模型开始出现问题的临界点大约在 10k 步长标记处。
多图指令跟随
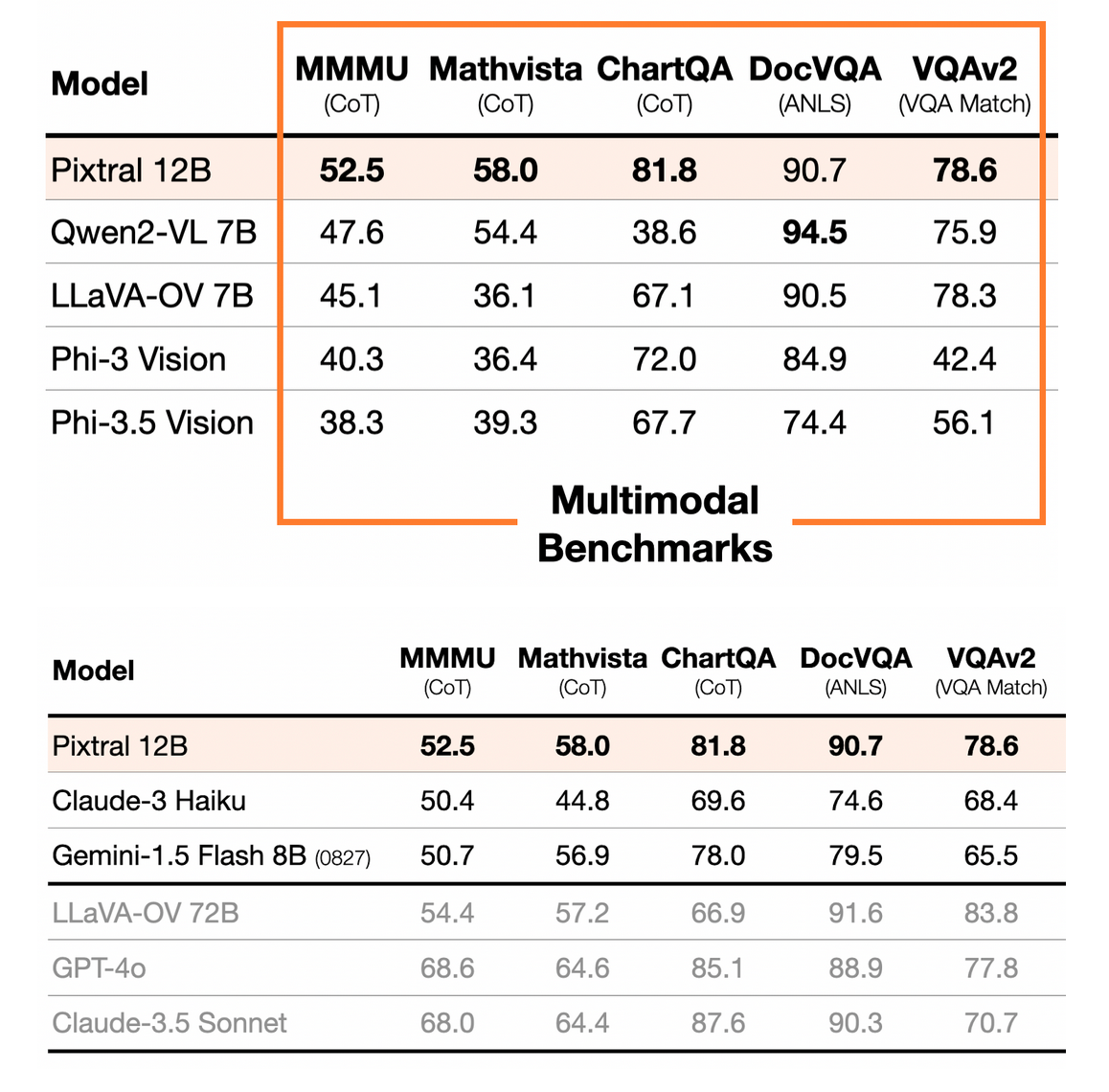
prompts:将两个表中的信息合并到单个 markdown 表中
回复:为了将两个表中的信息合并到一张表中,我们需要对齐每个基准中的模型及其对应的分数。以下是合并后的表格:

图像转代码
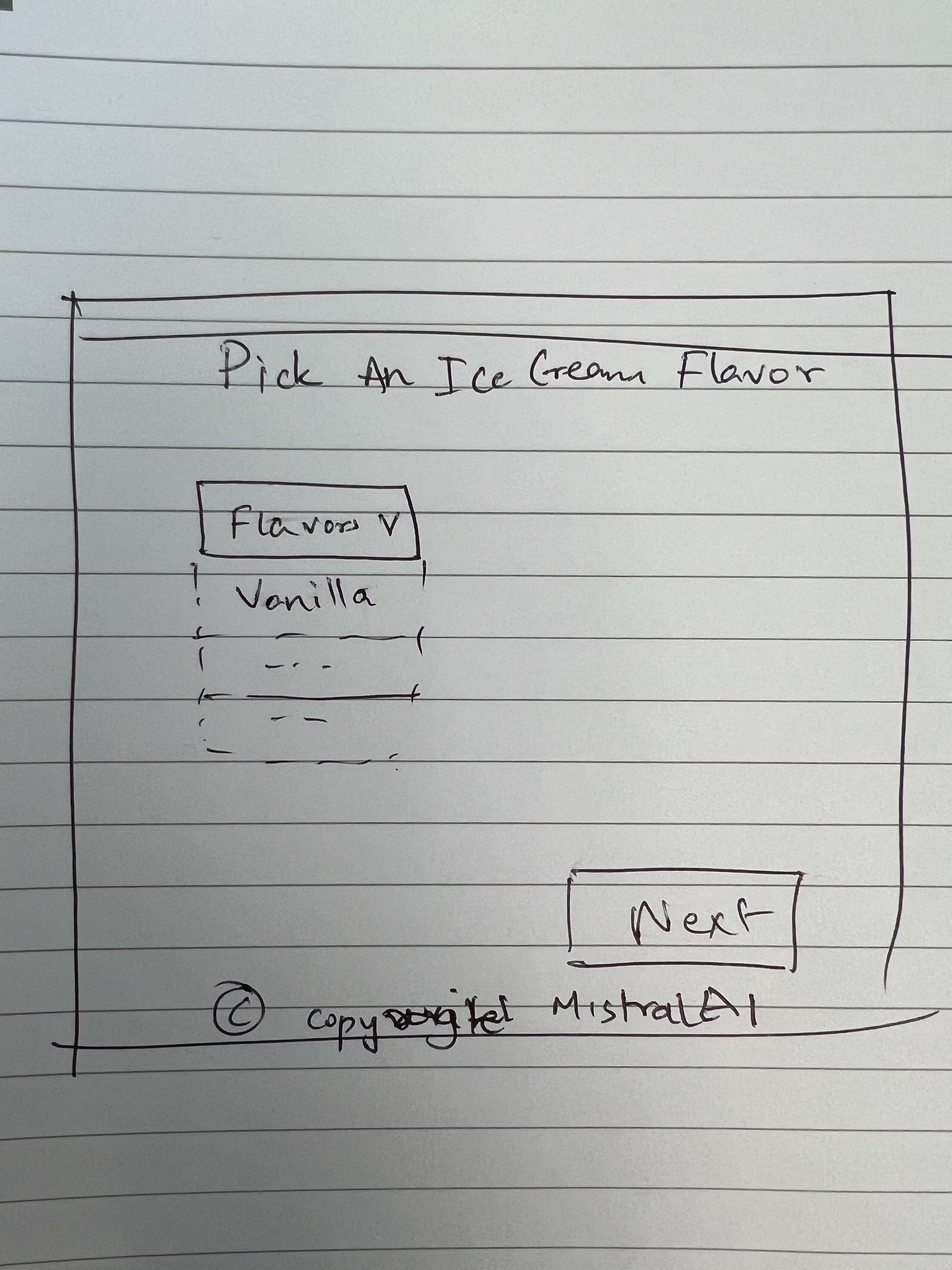
prompts:编写 HTML 代码来创建像这样的网站
回复:当然可以!下面是创建简单网页的 HTML 代码示例,该网页允许用户选择冰淇淋口味。此示例包含一个用于选择口味的下拉菜单和一个“下一步”按钮。
Pick an Ice Cream Flavor
Pick An Ice Cream Flavor
VanillaChocolateStrawberryCookie DoughMint Chocolate Next
© copyright MistralAI
#### 解释 - HTML 结构:网页由一个包含标题的容器 div、一个下拉菜单和一个按钮组成。
-
CSS 样式:应用基本样式来使内容居中并为元素设置样式。
-
JavaScript 函数:单击“下一步”按钮时,将调用
next函数。它会从下拉菜单中检索所选的口味,并显示所选口味的警报。
自然场景理解
-
比萨斜塔

提示: 这个人真的很大吗,或者这座建筑真的超级小吗?
回复:图片显示一个人将拇指放在比萨斜塔前,看起来拇指比斜塔大得多。这造成了一种视觉错觉,使斜塔看起来比实际要小。实际上,比萨斜塔是一座巨大而标志性的建筑,而这个人的拇指远没有图片中看起来那么大。这张照片的目的是通过将斜塔与拇指等熟悉的物体进行比较来展示斜塔令人印象深刻的高度和大小。
相关链接
主页介绍:https://mistral.ai/news/pixtral-12b/?continueFlag=cd1674d0e6cf893c868c7e71e63fbaab
线上体验:https://auth.mistral.ai/ui/login?flow=65b41b1d-2667-4c85-9623-da818dd233b6
模型下载:https://huggingface.co/mistralai/Pixtral-12B-2409?continueFlag=cd1674d0e6cf893c868c7e71e63fbaab